
В Apache Spark есть функции для кэширования промежуточных данных с целью получения повышения производительности при выполнении SQL запросов. В этой статье мы сравним различные методы кэширования в Spark, их преимущества, а также как ведут себя кэшированные большие данные (Big Data).
Как кэшировать данные в Apache Spark
Для кэширования данных в Apache Spark применяется методы cache или persist. Первый метод кеширует в оперативной памяти, а второй на выбор в зависимости от переданного аргумента. Рекомендуем использовать именно второй метод.
Код для кэширования данных в Spark выглядит следующим образом:
from pyspark.storagelevel import StorageLevel
data = spark.read.csv("file.csv", header=True, inferSchema=True)
data.persist(StorageLevel.MEMORY_ONLY_SER)
Можете проверить выполнилось ли кэширования, вызвав следующую атрибут:
data.is_cached # True
А также чтобы проверить, что кэширование выполнилось в памяти:
data.storageLevel.useMemory # True
Когда кэшировать данные в Apache Spark
Хорошее правило: определите DataFrame, который вы будете повторно использовать в своем приложении Spark, а затем произведите кэширование. Даже если считаете, что памяти недостаточно для всех данных, все равно попробуйте. Spark настойчиво будет кэшировать всё, что может, в памяти, а остальное перенесет на диск.
В чем польза кэширования
К основным преимуществам кэширования данных в Apache Spark относятся:
- Чтение данных из некоторых источников (hdfs:// или s3://) занимает время. Поэтому после чтения и применения стандартных операций, кеширование поможет вам повторно использовать данные
- Путем кэширования вы создаете некую контрольную точку в Spark приложении, и если в дальнейшем не удастся выполнить какую-либо задачу, приложение сможет повторно вычислить потерянный раздел RDD из кэша
- Если у вас недостаточно памяти, данные будут кэшироваться на локальном диске исполнителя, что также будет быстрее, чем чтение из удаленных источников
Методы кэширования
В Spark можно использовать разные уровни хранения для кеширования данных. К ним относятся:
DISK_ONLY: данные сохраняются на диске в сериализованном форматеMEMORY_ONLY: данные сохраняются в оперативной памяти в десериализованном форматеMEMORY_AND_DISK: данные сохраняются в оперативной памяти, и если памяти недостаточно, вытесненные блоки будут сохранены на дискеOFF_HEAP: данные сохраняются в памяти вне кучи
Мы также можем указать, следует ли сериализовать данные при хранении путем добавления SER в конце, например, MEMORY_ONLY_SER. Использование сериализованного формата увеличит время обработки, но уменьшит объем памяти.
Мы также можем указать, следует ли использовать репликацию (копирование и сохранение данных) при кэшировании. В конце добавляется 2, например, DISK_ONLY_2, MEMORY_AND_DISK_2.
И репликация, и сериализация вместе также возможны, например, MEMORY_AND_DISK_SER_2. В таблице показано разница между метода кэширования.
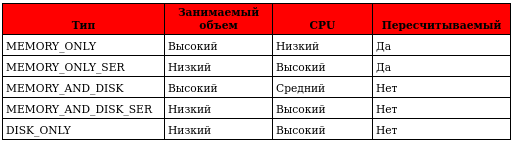
Все эти методы лежат к классе StorageLevel. В примере выше мы произвели кэширование в оперативной памяти в сериализованном виде.
Кэширование очень хорошо подходит для больших данных (Big Data). На кэшированном датасете размером 12 Гб операция фильтрация, а затем подсчет количества строк в Spark заняло в два раза меньше времени, чем на некэшированном. Код для приведенных вычислений в Spark следующий:
data.where("CheckoutType == 'Horizon' AND CheckoutYear == 2010").count()
А вот на датасете размером 2 Гб ситуация поменялась в другую сторону операции над кэшированными данными выполнились в три раза дольше (2 минуты против 6). Поэтому будьте внимательны к тому, с какими данными работаете.
О кэшировании и настройке конфигурации Spark на примерах реальных задачах Data Science вы узнаете на специализированном 2-дневном практическом курсе по машинному обучению «Основы Apache Spark для разработчиков и аналитиков Big Data» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

