
В прошлой статье мы говорили об устройстве оптимизатора Apache Spark. Теперь мы знаем, как сложный и продуманный механизм оптимизации Spark обеспечивает быстрый и эффективный анализ...

Как работает SparkSQL изнутри и причем здесь Catalyst
Spark обрабатывает данные быстро. Это было основным преимуществом фреймворка с момента его первого представления в 2010 году. Обладая широким спектром вариантов возможностей и простотой использования,...
3 метода параллельной обработки данных в Spark
Spark, как инструмент анализа данных, отлично подходит при увеличении масштаба задач и при увеличении размера самих данных Пока вы используете датафреймы и библиотеки Spark вы...

Выбор наилучшей модели: кросс-валдиация и разбиение на выборки
Тюнинг, или подбор параметров, является незаменимой частью при подборе модели Machine Learning, поскольку с одними параметрами модель может показывать высокие результаты, а с другими —...

Конвейеры машинного обучения в Spark
Построение моделей машинного обучения в Spark — это последовательный процесс. Сегодня мы расскажем о конвейерах (Pipeline) в Spark. Читайте далее: какие объекты используются в конвейере,...
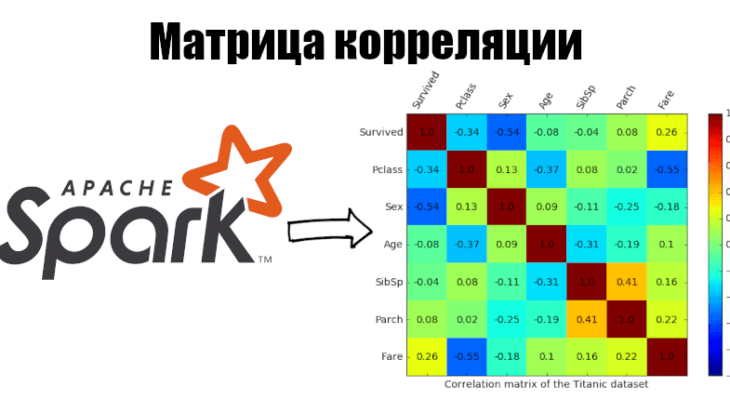
Статистка в Spark: корреляция
В рамках анализа данных и отбора признаков нередко вычисляется корреляция между признаками. Сегодня мы разберем, что такое корреляция, какие методы вычисления существуют, как найти коэффициенты...

Уменьшаем размерность с PCA в Spark
Что делать, если признаков в датасете слишком много для обучения модели Machine Learning (в том числе в Spark)? Один из вариантов — уменьшить размерность. Сегодня...

RFormula: Возможности языка R в Spark
Для подготовки датасета и векторизации признаков в Spark пригодиться класс RFormula. Читайте далее, как векторизовать данные, как записывать формулы, какие операторы поддерживаются, а также как...

Векторы в PySpark: основы векторных преобразований
Подготовка датасетов в PySpark — одна из задач, которую необходимо выполнить для последующего анализа данных или обучения моделей Machine Learning. Сегодня мы поговорим о работе...