
В прошлый раз мы говорили про главные функции для анализа датафреймов в Spark. В этой статье мы поговорим о том, как осуществляется взаимодействие Apache Spark и Pandas. Также рассмотрим на практических примерах, чем отличается Spark-датафрейм от датафрейма в Pandas.
В чем разница между Spark и Pandas: основное отличие в обработке данных
Мы уже говорили, что приложения, которые создаются на базе архитектуры Spark, имеют распределенную структуру, которая позволяет им запускаться как на локальной машине, так и на удаленном сервере. При этом Apache Spark не использует индексы для доступа к элементам датафрейма (dataframe). В Пандас все обстоит совсем иначе: эта Python-библиотека не предназначена для распределенных вычислений. Ее основная задача – это анализ и манипулирование большими данными. Доступ к данным происходит с помощью специальных индексов, которые генерируются при считывании данных из файла или при создании датафрейма вручную. Поэтому манипуляции с данными в Pandas занимают меньше времени. При этом все вычисления происходят только на локальной машине без возможности работы в кластере. Однако, бывают ситуации, когда нужно конвертировать датафрейм из Spark в Pandas для быстрого анализа данных. Для этого в Spark есть специальный метод toPandas().

Преобразование датафрейма из Spark в Пандас и обратно: парочка практических примеров
Для того, чтобы работать с библиотекой Pandas, необходимо ее импортировать в рабочую среду:
import pandas as pd
Теперь давайте создадим датафрейм в Spark для последующей конвертации в Пандас:
my_schema = StructType( [ StructField( 'id', IntegerType(), True),\
StructField('name',StringType(),True),\
StructField( 'age', IntegerType(), True),\
StructField( 'country', StringType(), True),])
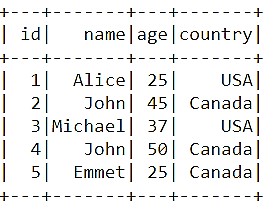
data_2 = spark.createDataFrame([(1,'Alice', 25, 'USA'),(2, 'John', 45, 'Canada'),(3, 'Michael', 37, 'USA'),
(4, 'John', 50, 'Canada'),
(5, 'Emmet', 25, 'Canada')],\
['id', 'name', 'age', 'country'], my_schema)
С помощью метода toPandas() конвертируем Spark-датафрейм:
pandas_data = data_2.toPandas() pandas_data.head()
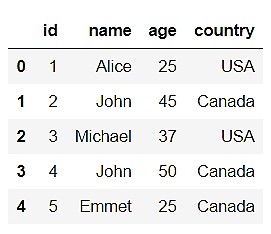
Как видим, у преобразованного датафрейма появились индексы слева от поля «id». Это и есть те самые индексы, которые генерируются библиотекой Pandas при создании датафрейма для быстрого доступа к данным. Теперь давайте выберем все строки со значением «Canada» в столбце «country»:
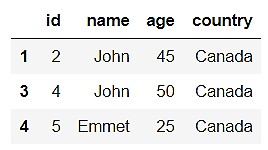
new_data = pandas_data.query( 'country == "Canada"') new_data.head()
Можно конвертировать преобразованный датафрейм обратно в Spark следующим образом:
spark_data = spark.createDataFrame(new_data) spark_data.show()

Таким образом, при обратном конвертировании преобразованные данные полностью сохранились. Это говорит о хорошей совместимости Apache Spark и Python-библиотеки Пандас.
Таким образом, благодаря интеграции с Пандас, Apache Spark позволяет вести более эффективный анализ больших данных, что делает его весьма полезным инструментом для Data Scientist’а и разработчика Big Data приложений. В следующей статье мы поговорим про две знаменитые файловые системы, с которыми работает Spark.
Более подробно про применение Apache Spark в проектах анализа больших данных, разработки Big Data приложений и прочих прикладных областях Data Science вы узнаете на практических курсах по Spark в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве.

