В прошлой статье мы говорили о случайном лесе в Apache Spark. Сегодня рассмотрим еще один ансамблевый алгоритм машинного обучения – градиентный бустинг (Gradient Boosting). Читайте в этой статье: принципы работы градиентного бустинга, его отличия от адаптивного бустинга (AdaBoost), примеры использования для решения задачи классификации и регрессии через Spark ML.
Терминология
Градиентный бустинг, он же Gradient Boosting, Gradient Boosted-Tree, более правильно будет назвать ансамбль деревьев решений, обученный с использованием градиентного бустинга.
Градиентный бустинг представляет собой ансамбль деревьев решений. В основе данного алгоритма лежит итеративное обучение деревьев решений с целью минимизировать функцию потерь. Благодаря особенностям деревьев решений градиентный бустинг способен работать с категориальными признаками , справляться с нелинейностями.
В Spark Ml градиентный бустинг поддерживает бинарную классификацию и регрессию с использованием как непрерывных признаков, так и категориальных. Деревья решений создаются на основе деревьев решений из Spark Ml (о них тут).
Gradient-Boosted Trees не поддерживает многоклассовую классификацию. Если вам она нужна, то используйте случайный лес (Random Forest).
Принципы работы градиентного бустинга
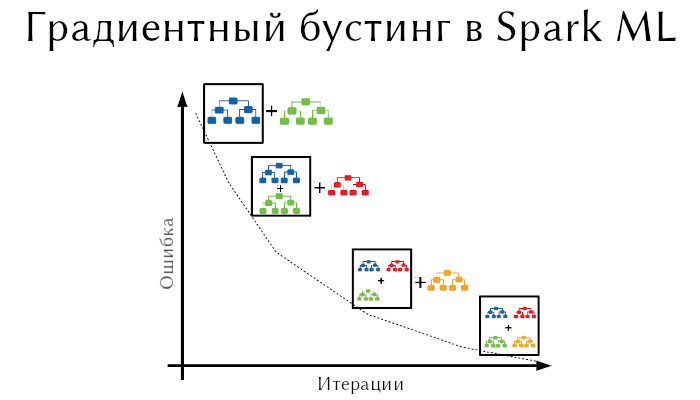
Бустинг – это метод преобразования слабообученных моделей в хорошообученные. В бустинге каждое новое дерево обучается на модифицированной версии исходного датасета. Градиентный бустинг схож на алгоритм адаптивного бустинга (AdaBoost).
AdaBoost обучает дерево, в котором каждому наблюдению присваивается вес. После оценки дерева увеличиваются веса тех наблюдений, которые сложно классифицировать, и уменьшаются веса тех, которые легко классифицировать. Следующее дерево опирается на эти скорректированные веса. Таким образом, текущую модель можно обозначить как Tree 1 + Tree 2. Затем подсчитывается ошибка этой модели и создается следующее дерево для выдачи новых предсказаний. Этот процесс продолжается столько раз, сколько указано. Последующие деревья помогают нам классифицировать наблюдения, которые плохо классифицируются предыдущими деревьями (или найти значение, если это регрессия). В результате прогнозы окончательной ансамблевой модели представляют собой взвешенную сумму прогнозов, сделанных предыдущими деревьями.
Gradient Boosting обучает множество моделей постепенно, аддитивно и последовательно. Разница между градиентном и адаптивном бустинге заключается в том, как алгоритмы идентифицируют слабые модели. AdaBoost выявляет их на основании высоких значений весов, а GB – на основании градиентов функции потерь. Как мы знаем, функция потерь – это мера, которая показывает насколько хорошо коэффициенты модели соответствуют базовым данным. Поэтому выбор той или иной функции потерь в этом алгоритме машинного обучения важен.
Функции потерь
В Spark Ml для градиентного бустинга предусмотрены три функции потерь: 1 для классификации и 2 для регрессии. Ниже приведена таблица с функциями потерь, где N – это количество наблюдения, y_i – класс/значение наблюдения i, x_i – признаки наблюдения i, F(x_i) – предсказанный класс/значение наблюдения i.
| Потеря | Задача | Формула | Описание |
|---|---|---|---|
| Логистическая потеря (log loss) | Классификация | Применяется только в бинарной классификации | |
| Квадратическая ошибка | Регрессия | L2-потери. Стоит по умолчанию | |
| Абсолютная ошибка | Регрессия | L1-потери |
Параметры градиентного бустинга
Перечислим параметры, характерные для градиентного бустинга (о параметрах деревьев решений узнаете тут).
lossType– функция потерь из таблицы выше. ДляGBTRegressorэто либоsquaredилиabsolute, дляGBTClassifierэтоlogistic.maxIter– количество итераций для проведения обучения (эквивалентно количеству деревьев).stepSize– параметр обучения. Лучше не трогать, в крайнем случае значение можно понизить. По умолчанию 0.1.
Пример градиентного бустинга в Apache Spark
Воспользуемся датасетом с данными о кредитном рейтинге. На основании различных характеристик (зарплата, семейное положение и т.д.) человек имеет либо дадут кредит(1) или нет (0).
Прежде всего векторизуем признаки, а затем разделим датасет на тренировочную и обучающую выборки. Код для подготовки датасета в Apache Spark:
from pyspark.ml.feature import VectorAssembler
df = spark.read.csv("credit.csv",
header=True,
inferSchema=True)
cols = df.columns.copy()
cols.remove("creditability")
va = VectorAssembler(
inputCols=cols,
outputCol="features"
).transform(df)
train, test = va.randomSplit([0.8, 0.2])
Теперь на тренировочной выборки обучим алгоритм градиентный бустинга для классификации кредитного рейтинга. Для этого используется класс GBTClassifier. Код для обучения градиентного бустинга в Apache Spark:
from pyspark.ml.classification import GBTClassifier
classifier = GBTClassifier(
labelCol="creditability",
featuresCol="features",
maxIter=20
)
model = classifier.fit(train)
Поскольку градиентный бустинг в Spark Ml может только проводить бинарную классификацию, то воспользуется метрикой BinaryClassificationEvaluator:
from pyspark.ml.evaluation import BinaryClassificationEvaluator pred = model.transform(test) evaluator = BinaryClassificationEvaluator(labelCol="creditability") accuracy = evaluator.evaluate(pred) print(accuracy) # У меня показало 0.73
Для решения задачи регрессии используется GBTRegressor. Пример кода для обучения градиентного бустинга в регрессионной задачи выглядит так:
from pyspark.ml.regression import GBTRegressor
regressor = GBTRegressor(
labelCol="amount",
featuresCol="features",
lossType="absolute",
maxIter=20,
)
model = regressor.fit(train)
# Остальное все тоже самое
Еще больше примеров обучения моделей в Apaceh Spark вы узнаете на специализированном курсе по машинному обучению «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

