Статистика является неотъемлемой частью анализа данных, так как позволяет найти отношения между признаками. Сегодня поговорим о статистических функциях библиотеки Spark MLlib. Читайте в этой статье: как вычислить сводные статистические данные, как найти корреляцию между признаками, а также как получить стратифицированную выборку в Apache Spark.
Сводные статистические данные
Сводные статистические данные в Spark MLlib могут быть получены через экземпляр класса MultivariateStatisticalSummary, который включает такие методы как:
count– количество записей,numNonzeros– количество ненулевых значений,max– максимальное значение,min– минимальное значение,mean– среднее значение,variance– отклонение,normL1– L1-норма для каждого признака (сумма абсолютных значений),normL2– L2-норма для каждого признака (сумма квадратов).
Экземпляр этого класса создается с помощью функции colStats модуля MLlib.stat.
На Scala сводные статистические данные могут быть получены следующим образом:
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
val observations = sc.parallelize(
Seq(
Vectors.dense(1.0, 10.0, 100.0),
Vectors.dense(2.0, 20.0, 200.0),
Vectors.dense(3.0, 30.0, 300.0)
)
)
// Вычисление сводной статистики для столбцов (признаков)
val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)
println(summary.mean) // вектор со средними значениями столбцов
println(summary.variance) // отклонение в каждом столбце
println(summary.numNonzeros) // кол-во ненулевых значений для каждого столбца
Тот же самый пример вычисления сводной статистики в Spark MLlib может быть выполнен и на языке Python:
from pyspark import SparkConf, SparkContext
from pyspark.mllib.stat import Statistics
import numpy as np
conf = SparkConf() \
.setAppName("BasicStatistics") \
.setMaster("local[*]")
sc = SparkContext(conf=conf)
mat = sc.parallelize([
np.array([1.0, 10.0, 100.0]),
np.array([2.0, 20.0, 200.0]),
np.array([3.0, 30.0, 300.0])
])
# Compute column summary statistics.
summary = Statistics.colStats(mat)
print(summary.mean())
print(summary.variance())
print(summary.numNonzeros())
Полученные результаты:
[ 2. 20. 200.] [1.e+00 1.e+02 1.e+04] [3. 3. 3.]
Корреляция в Spark MLlib
В одной из статей мы подробно говорили о корреляции, но уже в Spark ML. Здесь мы приведем, как определяется корреляция между признаками в Spark MLlib. На данный момент в Apache Spark поддерживаются коэффициенты корреляции Пирсона (Pearson) и Спирмена (Spearman).
Нахождение корреляции осуществляется через класс тот же Statistics. В зависимости от входного типа, RDD[Double] или RDD[Vector], на выходе будет значение типа Double или корреляционная матрица соответственно.
Итак, если у вас есть два массива, корреляцию между которыми вам нужно найти, то передайте их в качестве аргументов метода corr класса Statistics:
import org.apache.spark.mllib.linalg._ import org.apache.spark.mllib.stat.Statistics import org.apache.spark.rdd.RDD val seriesX: RDD[Double] = sc.parallelize(Array(1, 2, 3, 3, 5)) // Оба массива должны быть одного размера. val seriesY: RDD[Double] = sc.parallelize(Array(11, 22, 33, 33, 555)) // Вычисление корреляции. Третим аргументом передайте метод вычисления: // Пирсона или Спирмена. val correlation: Double = Statistics.corr(seriesX, seriesY, "pearson") println(s"Correlation is: $correlation")
А если у вас целый набор признаков, тогда передайте его и уточните метод вычисления корреляции (Пирсона или Спирмена), а Apache Spark вернет матрицу корреляции между признаками; код на Scala:
val data: RDD[Vector] = sc.parallelize(
Seq(
Vectors.dense(1.0, 10.0, 100.0),
Vectors.dense(2.0, 20.0, 200.0),
Vectors.dense(5.0, 33.0, 366.0))
)
val correlMatrix: Matrix = Statistics.corr(data, "pearson")
println(correlMatrix.toString)
Код на Python для вычисления корреляции между признаками в Spark MLlib примерно такой же:
from pyspark.mllib.stat import Statistics
# Вычисление корреляции между двумя массивами
seriesX = sc.parallelize([1.0, 2.0, 3.0, 3.0, 5.0])
seriesY = sc.parallelize([11.0, 22.0, 33.0, 33.0, 555.0])
print("Correlation is",
Statistics.corr(seriesX, seriesY, method="pearson"))
# Вычисление матрицы корреляции
data = sc.parallelize([
np.array([1.0, 10.0, 100.0]),
np.array([2.0, 20.0, 200.0]),
np.array([5.0, 33.0, 366.0])
])
print(Statistics.corr(data, method="pearson"))
Полученные результаты выглядят следующим образом:
Correlation is 0.8500286768773001 [[1. 0.97888347 0.99038957] [0.97888347 1. 0.99774832] [0.99038957 0.99774832 1. ]]
Стратифицированная выборка (Stratified sampling)
В отличие от других статистических функций Spark MLlib, методы стратифицированной выборки sampleByKey и sampleByKeyExact, применяются для пар ключ-значение. Для стратифицированной выборки ключи можно рассматривать как метку, а значение – как определенный атрибут. Например, ключом может быть мужчина или женщина или идентификаторы документов, а соответствующие значения могут быть списком возрастов людей в популяции или списком слов в документах.
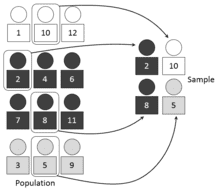
sampleByKey, можно сказать, подбрасывает монетку, чтобы решить, войдет ли наблюдаемая выборка в результирующую или нет. Этот метод требует одного прохода по данным и обеспечивает ожидаемый размер выборки. С другой стороны, метод sampleByKeyExact требует значительно больше ресурсов, но обеспечивает точный размер выборки с достоверностью 99,99%.
Метод sampleByKey позволяет приблизительно определить f_k * n_k элементов (округленное до большего), где f – это искомая дробь для ключа k, а n – это количество пар ключ-значение для каждого ключа k. Метод sampleByKeyExact определяет данное произведение точно.
Код на Scala для создания стратифицированной выборки в Spark MLlib:
val data = sc.parallelize(
Seq((1, 'a'), (1, 'b'), (2, 'c'), (2, 'd'), (2, 'e'), (3, 'f')))
// указание искомой дроби для каждого ключа
val fractions = Map(1 -> 0.1, 2 -> 0.6, 3 -> 0.3)
// Нахождение приблизительного значения
val approxSample = data.sampleByKey(
withReplacement = false, fractions = fractions)
// Нахождение точного значения
val exactSample = data.sampleByKeyExact(
withReplacement = false, fractions = fractions)
Метод sampleByKeyExact в настоящее время не поддерживается в Python API. Поэтому на Python стратифицированная выборка создается только через sampleByKey:
data = sc.parallelize([('A', 1), ('A', 10), ('A', 12),
('B', 2), ('B', 4), ('B', 6),
('B', 7), ('B', 8), ('B', 11),
('C', 3), ('C', 5), ('C', 9)])
fractions = {'A': 0.3, 'B': 0.2, 'C': 0.5}
approxSample = data.sampleByKey(False, fractions)
Результаты основываются на вероятности, поэтому после каждого выполнения кода они разные. Обратите внимание, и на Scala, и на Python первым аргументом передается логическая переменная, которая определяет переписать ли существующую выборку (при True) или создать новую (при False).
О том, как проводить базовую статистику в Apache Spark на прикладных примерах Data Science вы узнаете на специализированном курсе «Анализ данных с Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

