
В предыдущей статье мы немного рассказали о Spark NLP. В этой статье дадим обоснование использования данной библиотеки для решения любых задач NLP. Читайте далее, почему Spark NLP — один из богатых инструментов обработки данных на естественном языке: обучение с GPU с фреймворком глубокого обучения TensorFlow, передовые модели Machine Learning, готовность применяться в бизнесе.
Богатство инструментов
Spark NLP предоставляет простой API для интеграции с ML Pipelines для решения задач обработки текстов на естественном языке. Имеет множество алгоритмов машинного обучения; некоторые из них работают через фреймворк TensorFlow для глубокого обучения с поддержкой использования GPU. Также имеется разнообразные готовые предобученные модели.
Библиотека охватывает множество общих задач NLP, включая:
- токенизацию
- стемминг,
- лемматизацию,
- разбиение на части речи,
- анализ тональности,
- проверку орфографии,
- распознавание именованных сущностей и многое другое.
Spark NLP написана на Scala, но также имеет API для Python и Java. Используемые модели были выбраны в соответствии с самыми последними достижениями (state of the art). Их реализации следуют следующим критериям:
- Высокая точность.
- Высокая производительность.
- Обучаемость и настраиваемость (для каждого вида текста используются разные словари и грамматика, поэтому фреймворк должен работать для любых задач).
Вперед в production
Библиотека Spark ориентирована на то, что его пользователи (Data Scientist’ы) внедрят свои модели в бизнес клиента. Согласно опросу O’Reilly 2020 года Spark NLP по популярности обогнал такие библиотеки как spaCy и AllenNLP.
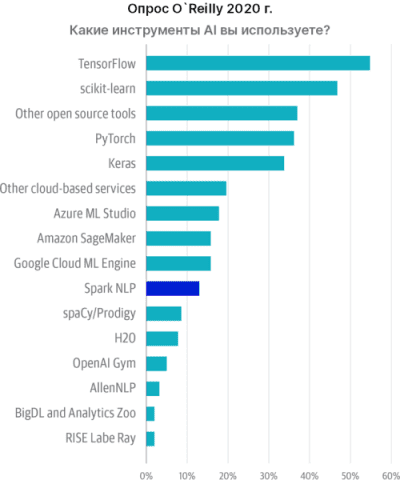
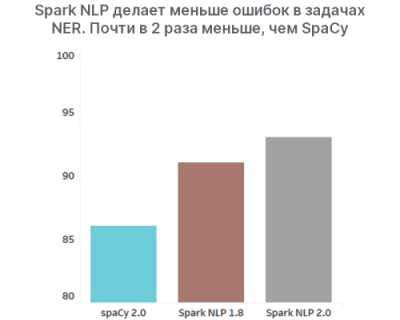
Являясь расширением Spark ML, библиотека хорошо интегрирована в Apache Spark. А с каждой новым релизом становится еще точнее, что контранстирует с spaCy.
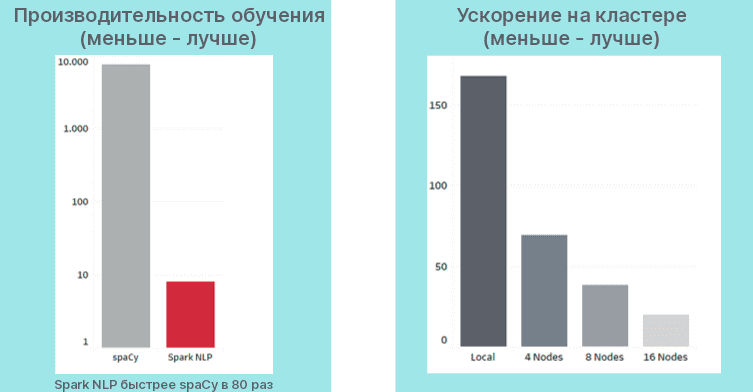
Быстрота вычислений превыше всего
По результатам сравнения обучения конвейера в Spark NLP и spaCy в одной из серии статей O’Reilly первая библиотека намного превосходит в десятки раз по времени выполнения как на локальном компьютере, так и на кластере.
В библиотеке возможно обучения на графическом процессоре (GPU). Под капотом, правда, находится фреймворк глубокого обучения TensorFlow. Причем использование GPU можно добиться одной строчкой:
import sparknlp spark = sparknlp.start()
Также в библиотеку входит пакет оптического распознавания символов OCR. Это первая NLP-библиотека, которая его поддерживает.
Желаете развиваться в области NLP и Machine Learning? У нас есть для вас специализированные курсы «PNLP: NLP – обработка естественного языка с python» и «Машинное обучение в Apache Spark», где вы узнаете о задачах NLP и применения алгоритмов машинного обучения на текстовых данных с реальными примерами из Big Data, в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

