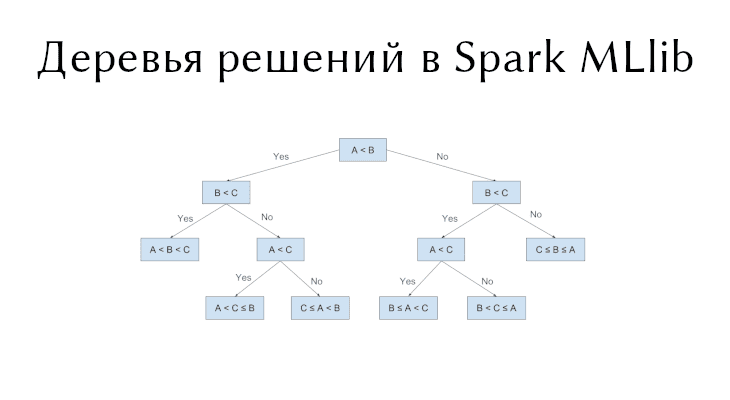
Деревья решений (Decision trees) являются одним из самых популярных алгоритмов машинного обучения и используются для задач классификации (бинарной и многоклассовой) и регрессии. Деревья решений простоты,...

Что такое деревья решений и для чего они нужны Spark’у
В прошлый раз мы говорили про особенности обработки файлов JSON в Spark. Сегодня поговорим про деревья решений в распределенном фреймворке Apache Spark. Читайте далее про...
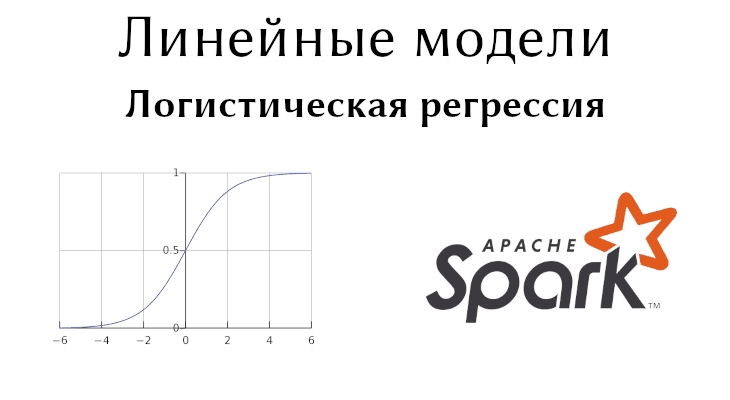
Линейные модели Sparl MLlib: Логистическая регрессия
В прошлой статье мы говорили о таком линейном алгоритме машинного обучения (Machine Learning), как метод опорных векторов. Сегодня рассмотрим второй линейный классификатор Spark MLlib –...
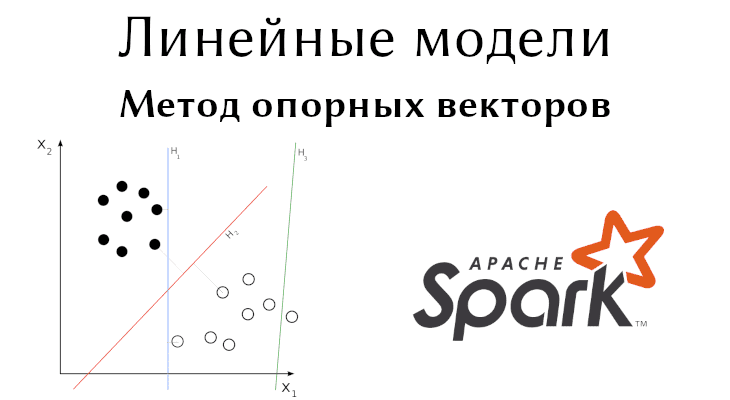
Линейные модели Sparl MLlib: Метод опорных векторов
Классификация – одна из главных задач машинного обучения (Machine Learning). Сегодня рассмотрим один из линейных классификаторов Spark MLlib – метод опорных векторов (SVM). В этой...

Компоненты Spark NLP
В предыдущей статье мы обсудили преимущества использования Spark NLP. Сегодня рассмотрим основные компоненты Spark NLP - аннотаторы (annotators), и как они связаны с Spark ML....

Зачем Data Scientist’у понадобится библиотека Spark NLP
В предыдущей статье мы немного рассказали о Spark NLP. В этой статье дадим обоснование использования данной библиотеки для решения любых задач NLP. Читайте далее, почему...

3 причины использовать библиотеку Spark NLP
Область NLP (Natural language processing) обладает широким спектром инструментов обработки текстовых данных. Одним из таких инструментов является Spark NLP. В этой статье мы расскажем вам...

10 вопросов на знание основ работы с логистической регрессией в Spark MLlib: открытый интерактивный тест для начинающих изучать машинное обучение
Чтобы самостоятельное обучение по Spark Mllib стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с логистической регрессией в распределенном фреймворке Apache...
3 метода параллельной обработки данных в Spark
Spark, как инструмент анализа данных, отлично подходит при увеличении масштаба задач и при увеличении размера самих данных Пока вы используете датафреймы и библиотеки Spark вы...

Выбор наилучшей модели: кросс-валдиация и разбиение на выборки
Тюнинг, или подбор параметров, является незаменимой частью при подборе модели Machine Learning, поскольку с одними параметрами модель может показывать высокие результаты, а с другими —...