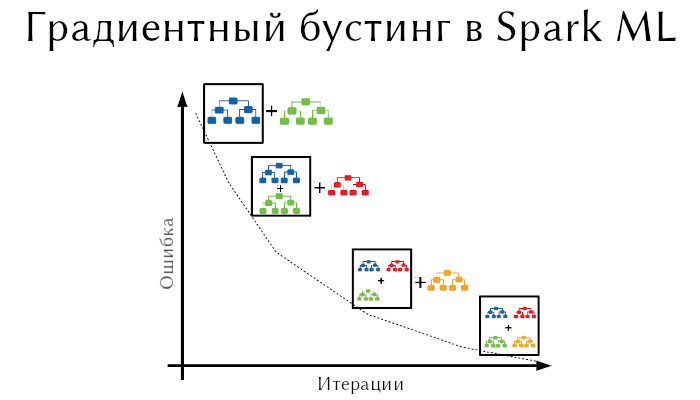
В прошлой статье мы говорили о случайном лесе в Apache Spark. Сегодня рассмотрим еще один ансамблевый алгоритм машинного обучения – градиентный бустинг (Gradient Boosting). Читайте...

Что такое архитектура распределенной среды Spark
В прошлый раз мы говорили деревья решений в Spark. Сегодня поговорим о том, как устроена распределенная архитектура Big Data фреймворка Apache Spark. Читайте далее про...

Ансамблевые алгоритмы Spark ML: Случайный лес
В предыдущей статье мы говорили о таком алгоритме машинного обучения, как деревья решений (Decision Trees). Сегодня рассмотрим ансамблевый алгоритм, который состоит из множества таких деревьев...
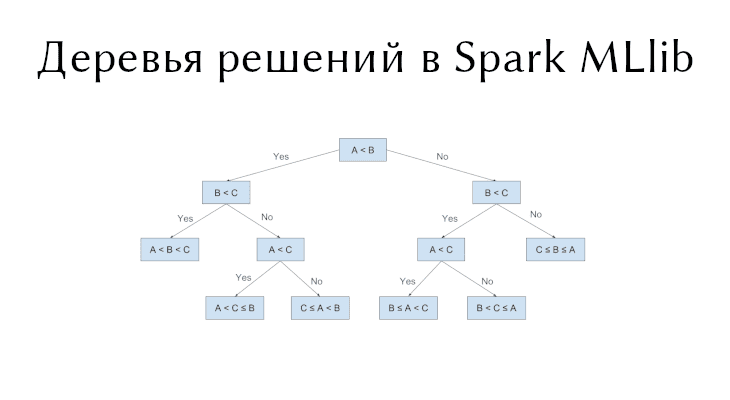
Деревья решений в Spark MLlib
Деревья решений (Decision trees) являются одним из самых популярных алгоритмов машинного обучения и используются для задач классификации (бинарной и многоклассовой) и регрессии. Деревья решений простоты,...

Что такое деревья решений и для чего они нужны Spark’у
В прошлый раз мы говорили про особенности обработки файлов JSON в Spark. Сегодня поговорим про деревья решений в распределенном фреймворке Apache Spark. Читайте далее про...

10 вопросов на знание основ взаимодействия Spark с реляционными СУБД: открытый интерактивный тест для начинающих
Чтобы самостоятельное обучение по Spark стало еще интереснее, сегодня мы предлагаем вам простой тест по основам взаимодействия фреймворка Spark с реляционными СУБД, включая базовые компоненты...
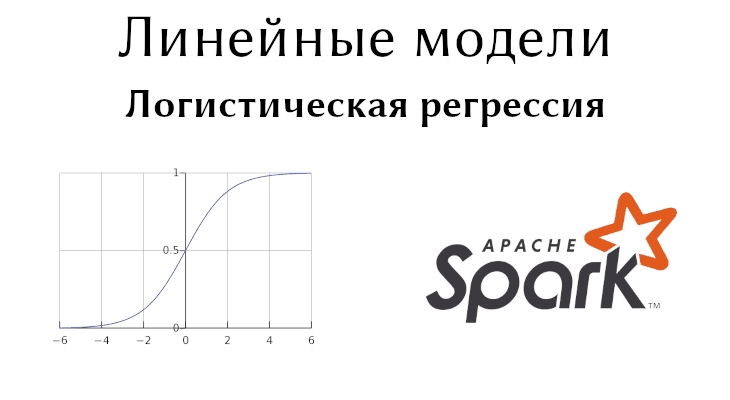
Линейные модели Sparl MLlib: Логистическая регрессия
В прошлой статье мы говорили о таком линейном алгоритме машинного обучения (Machine Learning), как метод опорных векторов. Сегодня рассмотрим второй линейный классификатор Spark MLlib –...
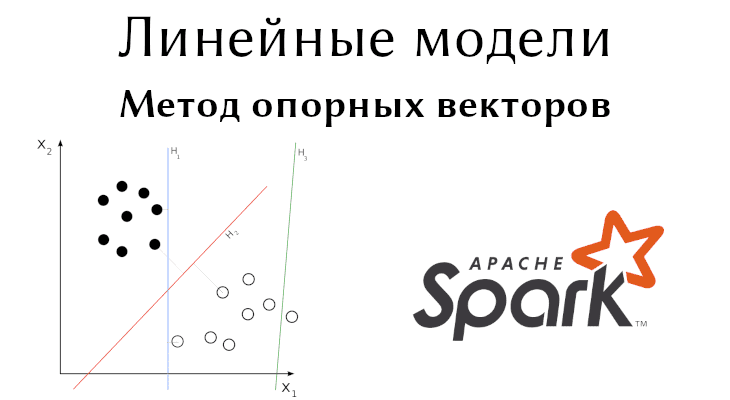
Линейные модели Sparl MLlib: Метод опорных векторов
Классификация – одна из главных задач машинного обучения (Machine Learning). Сегодня рассмотрим один из линейных классификаторов Spark MLlib – метод опорных векторов (SVM). В этой...

Как Spark работает со структурированными JSON-файлами
В прошлый раз мы говорили про особенности взаимодействия Big Data фреймворка Spark с реляционными СУБД. Сегодня поговорим о том, как Spark обрабатывает данные, которые подаются...
Проверка статистических гипотез с Spark MLlib
В прошлой статье мы говорили о базовой статистике в Apache Spark. Сегодня рассмотрим проверку статистических гипотез с помощью Spark MLlib с примерами кода на Python....