
В предыдущей статье мы говорили о таком алгоритме машинного обучения, как деревья решений (Decision Trees). Сегодня рассмотрим ансамблевый алгоритм, который состоит из множества таких деревьев и имеет название случайный лес (Random Forest). Читайте у нас: в чем случайность случайного леса, что такое бэггинг, а также как проводить обучение случайного леса в рамках классификации с помощью Spark ML1
Случайный лес – множество деревьев решений
Мы уже говорили о Decision Trees (деревья решений), но упомянем их еще раз, поскольку из них составляется Random Forest (случайный лес). Деревья решений – это обычное бинарное дерево, т.е. имеет каждый узел (кроме последних) имеет два потомка.
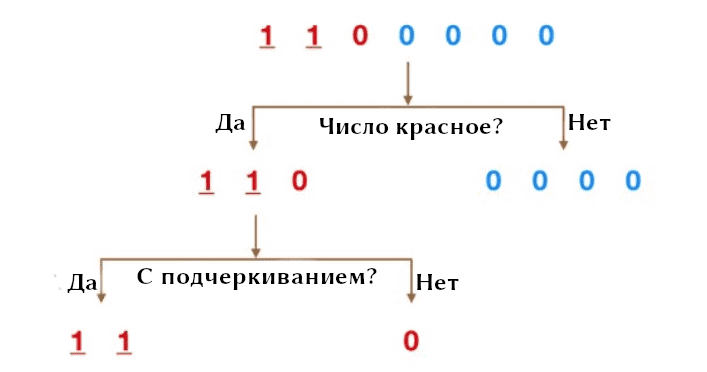
Представим, что есть датасет с числами: пять нулей и две единицы (см. рис). Требуется разбить классы по признакам. В данном случае признаками являются цвет (синий и красный) и знак подчеркивания. Теперь мы можем разбить сходный датасет сначала по цвету, а затем по подчеркиванию. Причем делается это в виде логического сравнения. Стоит заметить, что следующее разбиение происходит из предыдущего.
Случайный лес состоит из множества различных деревьев решений. Такая архитектура еще называется ансамблевой (ensemble) [1]. Каждое дерево предсказывает значения класса на основании своего разбиения, и выбирается то предсказание, которое получило наибольшее количество голосов (см. рис. ниже).
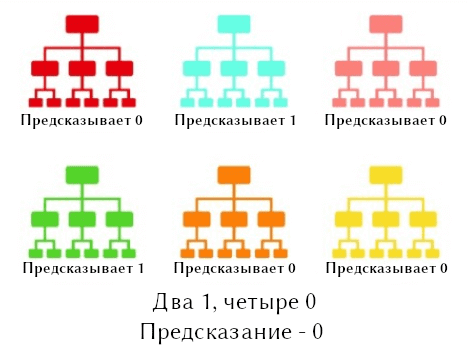
Исходя их этого, формулируется основной концепт случайного леса: Большое количество относительно некоррелированных моделей (деревьев), составляющих ансамбль, превосходит любую из отдельных моделей.
Случайность случайного леса
Как случайный лес гарантирует, что каждое отдельное дерево не слишком коррелирует с другим? Для построения используются следующие два метода (эти методы и отвечают на вопрос почему случайный лес случайный):
- Бэггинг (англ. bagging, сокращение от англ. bootstrap aggregation)
- Рандомизация признаков (Subsampling)
Деревья решений очень чувствительны к данным, на которых они обучаются – небольшие изменения в тренировочном наборе могут привести к существенно разным древовидным структурам. Случайный лес использует это преимущество, позволяя каждому отдельному дереву случайным образом выбирать из набора данных с некоторой заменой, в результате чего получаются разные деревья. Этот процесс известен как бэггинг.
При бэггинге тренировочные данные не разбиваются на более мелкие выборки. Напротив, если есть выборка размера N, то каждое дерево получает на вход выборку также с размером N. Вместо исходных данных берется случайная выборка размера N с заменой некоторых значений. Например, если исходные данные были [1, 2, 3, 4, 5, 6], то одному из деревьев можно, например, передать такие данные: [1, 2, 2, 3, 6, 6]. Обратите внимание, что оба списка имеют длину шесть и что “2” и “6” повторяются случайным образом.
В обычном дереве решений при разбиении узла рассматриваются все возможные признаки и выбирается тот, который дает наибольшее разбиение на левый и правый узел. А вот в случайном лесу каждое дерево разбивается на узлы из случайного подмножества признаков. Это приводит к еще большему разнообразию деревьев модели и, следовательно, к более низкой корреляции между деревьями. Такой подход называется рандомизацией признаков.
Как выносится решение случайного леса в Apache Spark
В Apache Spark обучать деревья решений можно производить отдельно, поэтому процесс обучения можно организовать параллельное обучение.
При прогнозировании случайный лес должен агрегировать предсказания из своего набора деревьев решений. Это агрегирование выполняется по-разному для классификации и регрессии.
- Классификация: голосование с большинством голосов. Прогноз каждого дерева учитывается как голосование за один класс; кто набрал большинство голосов, тот и будет предсказанным классом.
- Регрессия: усреднение значений. Каждое дерево предсказывает вещественное значение. Предсказанное значение будет средним значением всех деревьев.
Параметры случайного леса в Apache Spark
Мы не будем приводить некоторые параметры деревьев решений, поскольку их обсудили тут. Поэтому расскажем о параметрах случайного леса.
Первые два параметра являются наиболее важными, и их настройка часто может улучшить производительность:
numTrees– количество деревьев решений. Увеличение количества деревьев уменьшит дисперсию предсказанных значений. Время обучения увеличивается линейно при увеличении количества деревьев.maxDepth– максимальная глубина (или даже высота, если смотреть сверху вниз) каждого дерева решений. Увеличение глубины делает модель более эффективной. Однако для обучения глубоких деревьев требуется больше времени, и они более склонны к переобучению (overfitting).
Следующие два параметра обычно не требуют настройки. Однако с ними тоже поиграться для ускорения обучения.
subsamplingRate– этот параметр указывает размер набора данных как долю от размера исходного набора данных. Рекомендуется значение по умолчанию (1.0), но уменьшение этого значения ускорит обучение.featureSubsetStrategy– количество признаков, которые будут использоваться в качестве кандидатов на разбиение. Значение указывается в виде дробной части или функция от общего количества признаков. Уменьшение этого числа ускорит обучение, но иногда может повлиять на производительность, если оно слишком низкое.
Пример случайного леса в Spark ML
Мы используем датасет с данными о кредитоспособности. Так, человек на основании места работы, семейного положения, возраста, накоплений и еще 16 признаках определяется как кредитоспособный (1) или нет (0). Набор данных можно найти здесь в формате CSV.
Сформируем датасет в виде DataFrame, также соберем все признаки, кроме creditability (кредитоспособность), в один вектор признаков. Признак creditability будет нашим классом/меткой. Получившийся DataFrame разделим на тренировочную и тестовую выборки в пропорции 8:2. Весь код для подготовки датасета в Apache Spark выглядит так:
from pyspark.ml.feature import VectorAssembler
df = spark.read.csv("credit.csv",
header=True,
inferSchema=True)
cols = df.columns.copy()
cols.remove("creditability")
va = VectorAssembler(
inputCols=cols,
outputCol="features"
).transform(df)
train, test = va.randomSplit([0.8, 0.2])
Остается только обучить RandomForest на наших данных. В качестве меры неопределенности выберем gini, глубину дерева поставим равной 5, количество деревьев – 20. Пример кода для обучения случайного леса в Apache Spark:
from pyspark.ml.classification import RandomForestClassifier
classifier = RandomForestClassifier(
labelCol="creditability",
featuresCol="features",
impurity="gini",
maxDepth=5,
numTrees=20
)
model = classifier.fit(train)
Можем посмотреть, как был построен случайный лес, вызвав метод toDebugString. С помощью него убеждаемся, что глубина равна 5 по количеству вложенности if’ов.
print(model.toDebugString)
# Результат (но не весь):
Tree 0 (weight 1.0):
If (feature 1 <= 2.5)
If (feature 5 <= 4795.5)
If (feature 3 <= 1.5)
If (feature 8 <= 2.5)
If (feature 12 <= 2.5)
Predict: 0.0
...
Получение предсказаний случайного леса и подсчет точности классификации
Для получения предсказаний модели машинного обучения вызывается метод transform, который принимает тестовую выборку. Метод возвращает DataFrame со столбцом rawPrediction.
Для оценки модели Machine Learning в рамках бинарной классификации используется класс BinaryClassificationEvaluator. Он принимает в качестве аргумента название класса/метки, а уже для вычисления вызывается метод evaluate.
Пример кода для оценки точности модели машинного обучения в Apache Spark:
from pyspark.ml.evaluation import BinaryClassificationEvaluator pred = model.transform(test) evaluator = BinaryClassificationEvaluator(labelCol="creditability") accuracy = evaluator.evaluate(pred) print(accuracy)
Решение задачи регрессия отличается лишь тем, что для обучения случайного леса нужно будет создать объект класса RandomForestRegressor, а для оценки модели RegressionEvaluator
В следующей статье разберем алгоритм градиентного бустинга в Spark ML. А о том, как готовить датасеты, обучать модели в Apache Spark на реальных примерах Data Science вы узнаете на специализированном курсе по машинному обучению «Машинное обучение в Apache Spark» в лицензированном учебном центре обучения и повышения квалификации разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.

